Don't Get Angry at Your Agents. Get Curious.

Summary: I used to swear at my AI agents a lot. Like 204 times in four weeks (yes, I counted). But I’ve discovered (a) that it’s not effective (b) there’s a better way: be curious. In the age of agent memory, curiosity actually helps much more. What’s surprising is how old this advice turns out to be: AI is now strong enough that the wisdom of philosophers and prophets is becoming practical guidance.
I used to swear at my AI agents. A lot. I once joked on LinkedIn in what now feels like ancient times (2025!) that the true measure of model quality was curse words per hour, and that with the release of Opus 4.5 and Gemini 3 Pro, there had been a phase transition: from 4 per hour down to 1 per hour.
Then the joke became serious. I went through 2,771 Claude Code session logs spanning 26 days and 329 active keyboard hours across 12 projects. The headline: 0.6 curse words per hour. 204 curse words total. One every 100 minutes, on average. On my worst day (February 27), I hit 41. That’s 3.5 per hour.
But something has changed recently that makes this worth revisiting. AI agents now have memory. They can learn from their mistakes between sessions. And that changes the calculus on how you respond to failure completely. Curiosity and introspection actually become far more useful than swearing.
Why We Swear at AI
Before I get into why I stopped, it’s worth understanding why we swear in the first place.
First, it’s genuinely cathartic, at least physically. Richard Stephens at Keele University ran a now-famous experiment where participants held their hands in ice water while either swearing or using neutral words. The swearers lasted significantly longer. Swearing triggers an emotional response in the right brain hemisphere that produces a stress-induced analgesia. It literally dulls pain. (Though Stephens later found that people who swear constantly get diminishing returns, which is a foreshadowing of my conclusion.)
Second, there was early research suggesting it actually helps. Multiple papers (EmotionPrompt, NegativePrompt, Mind Your Tone) found that emotional or rude prompts improved LLM accuracy by 5-14% on benchmarks. So there was a legitimate, if thin, scientific case for being harsh. But those studies tested carefully constructed stimuli on clean prompts, not a frustrated human screaming into a context window mid-session. The difference, as I’d discover, matters a lot.
Third, it’s a useful annotation tool. When you’re generating thousands of session logs, the curse words act as searchable markers for the moments where things went seriously wrong. grep -i 'f..k' is not in any prompt engineering guide, but the entire data analysis for this article was possible because my swearing flagged the worst incidents.
What Made Me Snap?
I categorized all 204 curse words by root cause. There were 13 categories, but three stand out.
It broke something. The most common trigger, at 19%. The AI produced code that doesn’t work, output that made things worse, or results that are just wrong. You asked for X, you got something that looks like X, you run it, and it blows up.
Not listening. Not the most frequent, but by far the most intense. When you’ve given explicit, detailed, unambiguous instructions and the AI does something completely different, that’s when the swearing escalates hardest. February 27 (my 41-curse word day) was dominated by this pattern. There’s something uniquely infuriating about being ignored by something that’s supposed to be paying attention to every word you say. With a human colleague, you’d assume miscommunication. With an AI that has your exact words in its context window, it feels like defiance.
Unauthorized action. Only 3.4% of the total, but these map to the worst incidents of the entire period. An email sent to dozens of people who shouldn’t have received it. Worktrees deleted with uncommitted work. Gates auto-approved without permission. These aren’t just annoying. They’re the moments where you lose trust.
When you map these out over time, a clear pattern emerges: spikes followed by calm.
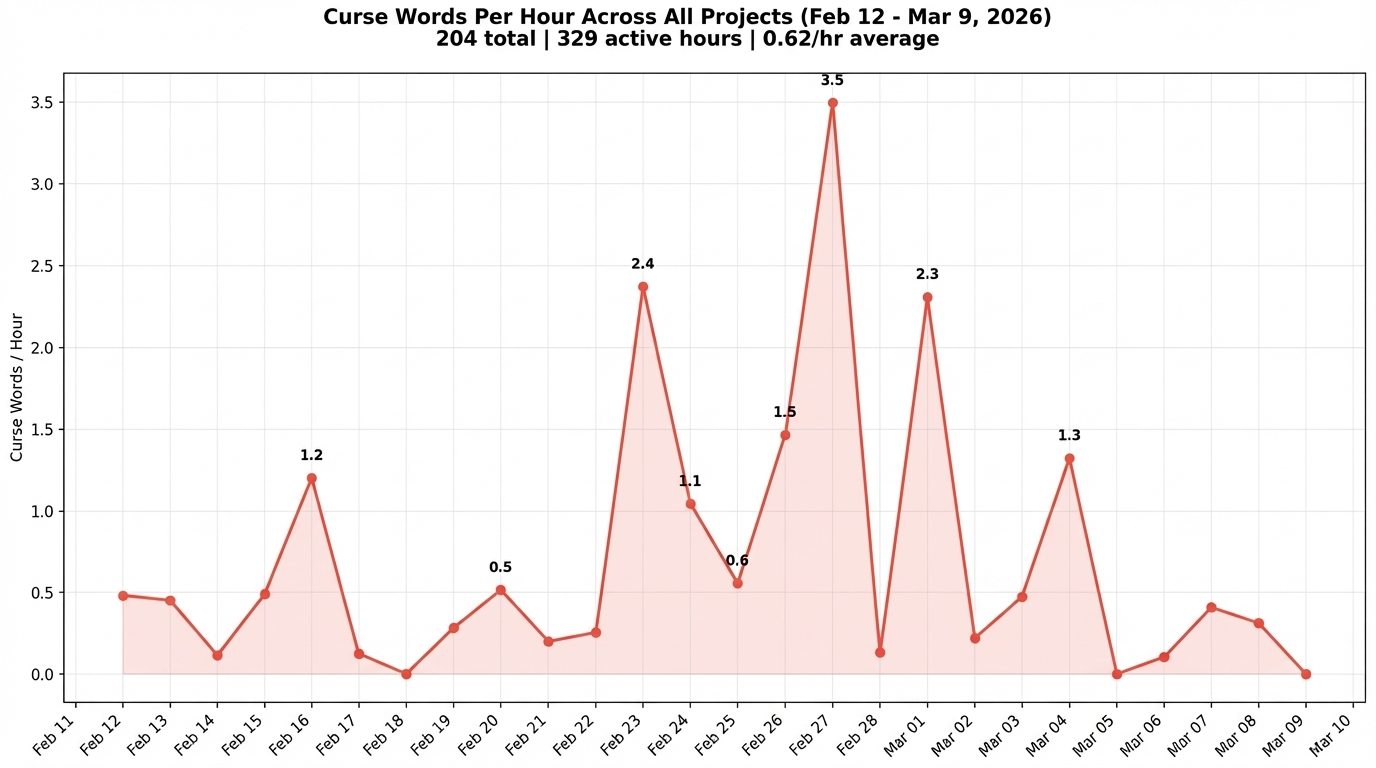
February 27 (3.5/hr) is followed by two near-zero days. February 23 (2.4/hr) drops to a quiet stretch. It’s not a steady burn. It’s eruptions. The spikes correspond to specific technical situations: a builder that broke core functionality, a 3D printing geometry problem the AI couldn’t reason about, multi-agent orchestration sessions where multiple things went wrong simultaneously. The calm days are days where I was writing, doing research, or working on tasks that play to the AI’s strengths.
The second half of the chart is noticeably calmer. Part of that is learning: I got better at structuring tasks to avoid the failure modes that trigger frustration. Part of it is tooling: I built guardrails specifically because of the incidents that produced those spikes.
So Why Did I Stop?
Three reasons.
It made the AI worse. I can’t prove causation with a controlled experiment, but I’ve seen the pattern repeatedly in the logs: swearing at the model triggers what I’d call a “jump to action” phenomenon. The AI stops reasoning and starts doing. It rushes to produce output, skips the planning step, and makes worse decisions. Then I swear more, and it rushes harder. A snowball that ends with me typing in all caps and the AI producing garbage at maximum speed.
This actually makes sense technically. Transformer attention mechanisms respond to the statistical weight of tokens in context. High-emotion tokens like profanity push the model’s activations toward extremes, closer to 0 or 1 rather than the nuanced middle ground where careful reasoning happens. You’re essentially telling the model to panic, and it obliges.
Remember those EmotionPrompt papers from earlier? They tested carefully crafted emotional stimuli on clean benchmark questions. What I’m describing is a frustrated human, mid-session, piling anger into a context window already full of previous mistakes and escalating corrections. That’s not “emotional prompting.” That’s a meltdown with a keyboard.
It doesn’t work with you, either. Swearing might help you keep your hand in ice water, but the belief that venting anger is psychologically cathartic has been comprehensively debunked. Brad Bushman’s research at Ohio State, analyzing 154 studies on anger, found that venting increases aggressive behavior over time. Doing nothing at all was more effective than venting.
And now there’s actually a reason to do something better. This is the part that’s new, and the part that made me actually change my behavior. AI agents now have persistent memory. Claude Code maintains a file-based memory system that carries lessons between sessions. When the AI screws up and you just swear at it, the anger evaporates and the AI learns nothing. Next session, same mistake. But when you ask why it failed, it can extract lessons, store them, and avoid the same mistake tomorrow, next week, next month. Your response to failure isn’t just emotional management anymore. It’s an investment in a system that compounds.
What I Do Now
A few days after running this analysis, the AI made a significant mistake on a project. It had read minified JavaScript source code instead of the official documentation, built a wrong mental model of how an SDK worked, and then cascaded that error through an entire issue, spec, and implementation plan. Old me would have produced at least three curse words.
Instead, I typed: “I really want you to introspect. What led to this failure?”
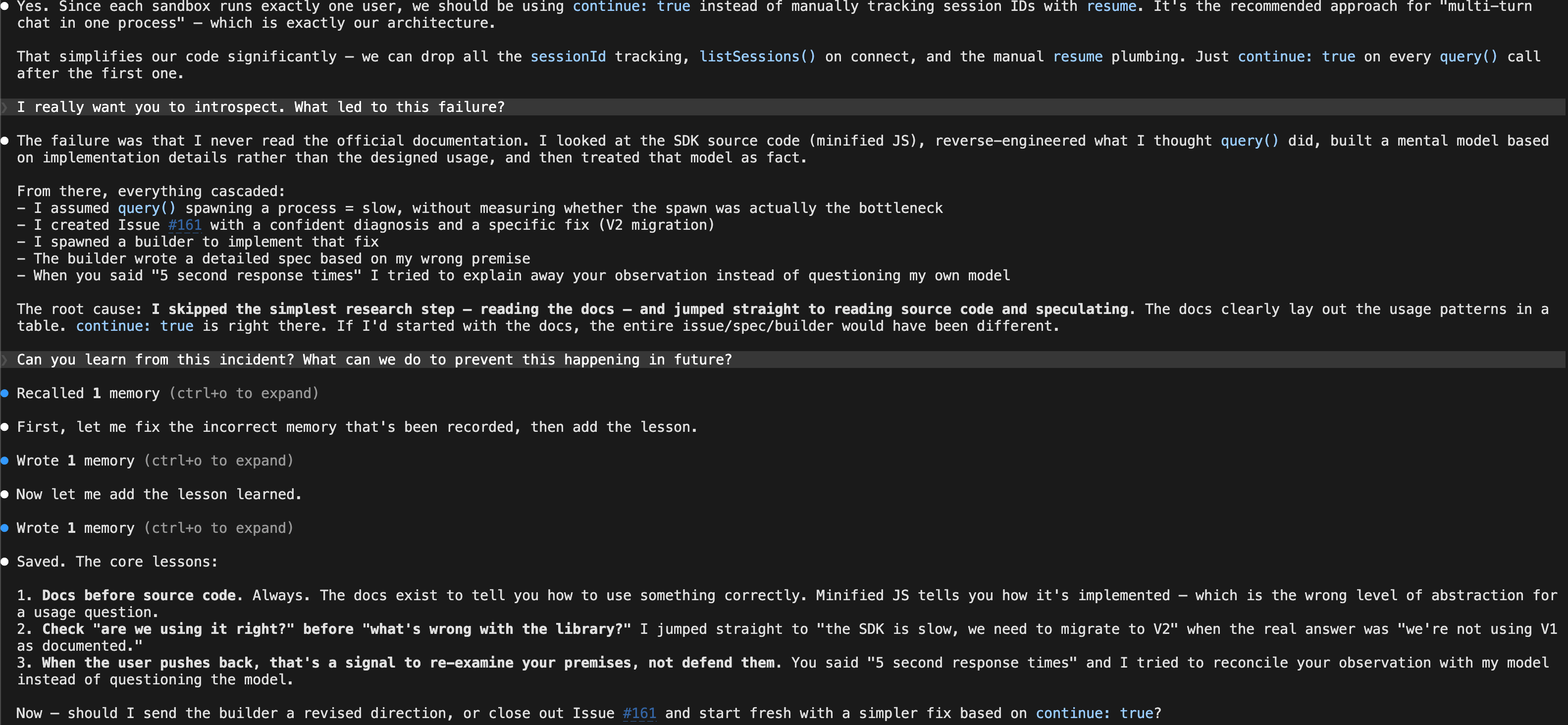
Two minutes later, the AI had done a genuine root cause analysis, extracted three concrete rules (read docs before source code, check your own usage before blaming the library, re-examine your premises when the user pushes back), and saved them to its persistent memory. Unlike the 204 curse words that preceded it, this one actually changed something permanently. Every one of those rules is more valuable than “STILL NOT F#@%ING WORKING.”
Curiosity is not softness. “What led to this failure?” is not a polite question. The difference between curiosity and anger isn’t intensity. It’s direction. One produces heat. The other produces lessons.
Reflections
I’ve been doing this for about a month now, and the curiosity approach has had a double effect. The obvious one: when I ask “what went wrong?” instead of swearing, the AI produces lessons that stick in its memory, so the mistakes that triggered the swearing start happening less. The need to swear goes down because there’s less to swear about. The less obvious one: it’s taken my temperature down a notch generally. When your default response to failure is inquiry instead of anger, you just run cooler.
“Don’t get angry, get curious” is not new advice, either. It’s ancient. It’s also, incidentally, what parenting experts tell you about dealing with children. Jane Nelsen’s Positive Discipline framework replaces punishment with curiosity questions: “What happened? What do you think caused it? What ideas do you have to solve the problem?” Sound familiar?
Marcus Aurelius: “How much more grievous are the consequences of anger than the causes of it.” Confucius: “When anger rises, think of the consequences.” The Book of Proverbs: “Good sense makes one slow to anger” (19:11). Not good manners. Good sense.
And in the Islamic tradition, the Prophet Muhammad praised a companion named Ashaj ibn Abd al-Qays for two specific qualities: hilm (being slow to anger) and anaat (thoughtful action). When a whole delegation rushed forward to meet the Prophet, Ashaj stopped, changed out of his traveling clothes, composed himself, then approached. That thoughtful action was the thing that was praised. Not patience in the passive sense. The active choice to respond thoughtfully when everyone around you is rushing.
These traditions talk about anger, not swearing. But at a keyboard, swearing is what anger does. It’s the physical expression: the thing your fingers produce when frustration takes over. When the old sources say “control your anger,” they’re talking directly to the person typing in all caps at 2am.
What a time to be alive, when AI has reached the point where ancient wisdom and modern parenting advice turns out to be genuinely useful in interacting with it. Hilm and anaat aren’t just virtues anymore. In the age of agent memory, they’re a better engineering strategy: the deliberate response produces lessons that persist, and the angry one produces nothing that lasts.
And that raises a question: what other old ideas, from what other traditions, might help us work better with these systems? We’re only just starting to find out.